Note
Click here to download the full example code
DCGAN Tutorial¶
Author: Nathan Inkawhich
Introduction¶
This tutorial will give an introduction to DCGANs through an example. We will train a generative adversarial network (GAN) to generate new celebrities after showing it pictures of many real celebrities. Most of the code here is from the dcgan implementation in pytorch/examples, and this document will give a thorough explanation of the implementation and shed light on how and why this model works. But don’t worry, no prior knowledge of GANs is required, but it may require a first-timer to spend some time reasoning about what is actually happening under the hood. Also, for the sake of time it will help to have a GPU, or two. Lets start from the beginning.
Generative Adversarial Networks¶
What is a GAN?¶
GANs are a framework for teaching a DL model to capture the training data’s distribution so we can generate new data from that same distribution. GANs were invented by Ian Goodfellow in 2014 and first described in the paper Generative Adversarial Nets. They are made of two distinct models, a generator and a discriminator. The job of the generator is to spawn ‘fake’ images that look like the training images. The job of the discriminator is to look at an image and output whether or not it is a real training image or a fake image from the generator. During training, the generator is constantly trying to outsmart the discriminator by generating better and better fakes, while the discriminator is working to become a better detective and correctly classify the real and fake images. The equilibrium of this game is when the generator is generating perfect fakes that look as if they came directly from the training data, and the discriminator is left to always guess at 50% confidence that the generator output is real or fake.
Now, lets define some notation to be used throughout tutorial starting with the discriminator. Let \(x\) be data representing an image. \(D(x)\) is the discriminator network which outputs the (scalar) probability that \(x\) came from training data rather than the generator. Here, since we are dealing with images the input to \(D(x)\) is an image of HWC size 3x64x64. Intuitively, \(D(x)\) should be HIGH when \(x\) comes from training data and LOW when \(x\) comes from the generator. \(D(x)\) can also be thought of as a traditional binary classifier.
For the generator’s notation, let \(z\) be a latent space vector sampled from a standard normal distribution. \(G(z)\) represents the generator function which maps the latent vector \(z\) to data-space. The goal of \(G\) is to estimate the distribution that the training data comes from (\(p_{data}\)) so it can generate fake samples from that estimated distribution (\(p_g\)).
So, \(D(G(z))\) is the probability (scalar) that the output of the generator \(G\) is a real image. As described in Goodfellow’s paper, \(D\) and \(G\) play a minimax game in which \(D\) tries to maximize the probability it correctly classifies reals and fakes (\(logD(x)\)), and \(G\) tries to minimize the probability that \(D\) will predict its outputs are fake (\(log(1-D(G(x)))\)). From the paper, the GAN loss function is
In theory, the solution to this minimax game is where \(p_g = p_{data}\), and the discriminator guesses randomly if the inputs are real or fake. However, the convergence theory of GANs is still being actively researched and in reality models do not always train to this point.
What is a DCGAN?¶
A DCGAN is a direct extension of the GAN described above, except that it explicitly uses convolutional and convolutional-transpose layers in the discriminator and generator, respectively. It was first described by Radford et. al. in the paper Unsupervised Representation Learning With Deep Convolutional Generative Adversarial Networks. The discriminator is made up of strided convolution layers, batch norm layers, and LeakyReLU activations. The input is a 3x64x64 input image and the output is a scalar probability that the input is from the real data distribution. The generator is comprised of convolutional-transpose layers, batch norm layers, and ReLU activations. The input is a latent vector, \(z\), that is drawn from a standard normal distribution and the output is a 3x64x64 RGB image. The strided conv-transpose layers allow the latent vector to be transformed into a volume with the same shape as an image. In the paper, the authors also give some tips about how to setup the optimizers, how to calculate the loss functions, and how to initialize the model weights, all of which will be explained in the coming sections.
from __future__ import print_function
#%matplotlib inline
import argparse
import os
import random
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.backends.cudnn as cudnn
import torch.optim as optim
import torch.utils.data
import torchvision.datasets as dset
import torchvision.transforms as transforms
import torchvision.utils as vutils
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.animation as animation
from IPython.display import HTML
# Set random seem for reproducibility
manualSeed = 999
#manualSeed = random.randint(1, 10000) # use if you want new results
print("Random Seed: ", manualSeed)
random.seed(manualSeed)
torch.manual_seed(manualSeed)
Out:
Random Seed: 999
Inputs¶
Let’s define some inputs for the run:
- dataroot - the path to the root of the dataset folder. We will talk more about the dataset in the next section
- workers - the number of worker threads for loading the data with the DataLoader
- batch_size - the batch size used in training. The DCGAN paper uses a batch size of 128
- image_size - the spatial size of the images used for training. This implementation defaults to 64x64. If another size is desired, the structures of D and G must be changed. See here for more details
- nc - number of color channels in the input images. For color images this is 3
- nz - length of latent vector
- ngf - relates to the depth of feature maps carried through the generator
- ndf - sets the depth of feature maps propagated through the discriminator
- num_epochs - number of training epochs to run. Training for longer will probably lead to better results but will also take much longer
- lr - learning rate for training. As described in the DCGAN paper, this number should be 0.0002
- beta1 - beta1 hyperparameter for Adam optimizers. As described in paper, this number should be 0.5
- ngpu - number of GPUs available. If this is 0, code will run in CPU mode. If this number is greater than 0 it will run on that number of GPUs
# Root directory for dataset
dataroot = "/home/ubuntu/facebook/datasets/celeba"
# Number of workers for dataloader
workers = 4
# Batch size during training
batch_size = 128
# Spatial size of training images. All images will be resized to this
# size using a transformer.
image_size = 64
# Number of channels in the training images. For color images this is 3
nc = 3
# Size of z latent vector (i.e. size of generator input)
nz = 100
# Size of feature maps in generator
ngf = 64
# Size of feature maps in discriminator
ndf = 64
# Number of training epochs
num_epochs = 5
# Learning rate for optimizers
lr = 0.0002
# Beta1 hyperparam for Adam optimizers
beta1 = 0.5
# Number of GPUs available. Use 0 for CPU mode.
ngpu = 1
Data¶
In this tutorial we will use the Celeb-A Faces dataset which can be downloaded at the linked site, or in Google Drive. The dataset will download as a file named img_align_celeba.zip. Once downloaded, create a directory named celeba and extract the zip file into that directory. Then, set the dataroot input for this notebook to the celeba directory you just created. The resulting directory structure should be:
/path/to/celeba
-> img_align_celeba
-> 188242.jpg
-> 173822.jpg
-> 284702.jpg
-> 537394.jpg
...
This is an important step because we will be using the ImageFolder dataset class, which requires there to be subdirectories in the dataset’s root folder. Now, we can create the dataset, create the dataloader, set the device to run on, and finally visualize some of the training data.
# We can use an image folder dataset the way we have it setup.
# Create the dataset
dataset = dset.ImageFolder(root=dataroot,
transform=transforms.Compose([
transforms.Resize(image_size),
transforms.CenterCrop(image_size),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]))
# Create the dataloader
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size,
shuffle=True, num_workers=workers)
# Decide which device we want to run on
device = torch.device("cuda:0" if (torch.cuda.is_available() and ngpu > 0) else "cpu")
# Plot some training images
real_batch = next(iter(dataloader))
plt.figure(figsize=(8,8))
plt.axis("off")
plt.title("Training Images")
plt.imshow(np.transpose(vutils.make_grid(real_batch[0].to(device)[:64], padding=2, normalize=True).cpu(),(1,2,0)))

Implementation¶
With our input parameters set and the dataset prepared, we can now get into the implementation. We will start with the weigth initialization strategy, then talk about the generator, discriminator, loss functions, and training loop in detail.
Weight Initialization¶
From the DCGAN paper, the authors specify that all model weights shall
be randomly initialized from a Normal distribution with mean=0,
stdev=0.2. The weights_init function takes an initialized model as
input and reinitializes all convolutional, convolutional-transpose, and
batch normalization layers to meet this criteria. This function is
applied to the models immediately after initialization.
# custom weights initialization called on netG and netD
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find('BatchNorm') != -1:
nn.init.normal_(m.weight.data, 1.0, 0.02)
nn.init.constant_(m.bias.data, 0)
Generator¶
The generator, \(G\), is designed to map the latent space vector (\(z\)) to data-space. Since our data are images, converting \(z\) to data-space means ultimately creating a RGB image with the same size as the training images (i.e. 3x64x64). In practice, this is accomplished through a series of strided two dimensional convolutional transpose layers, each paired with a 2d batch norm layer and a relu activation. The output of the generator is fed through a tanh function to return it to the input data range of \([-1,1]\). It is worth noting the existence of the batch norm functions after the conv-transpose layers, as this is a critical contribution of the DCGAN paper. These layers help with the flow of gradients during training. An image of the generator from the DCGAN paper is shown below.
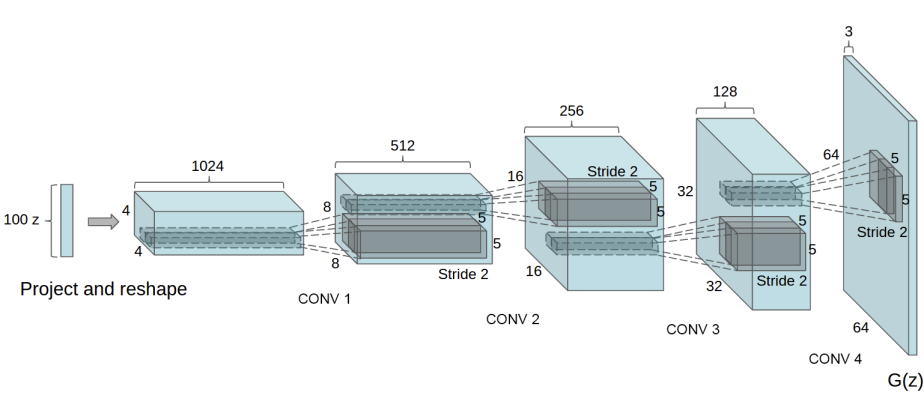
Notice, the how the inputs we set in the input section (nz, ngf, and nc) influence the generator architecture in code. nz is the length of the z input vector, ngf relates to the size of the feature maps that are propagated through the generator, and nc is the number of channels in the output image (set to 3 for RGB images). Below is the code for the generator.
# Generator Code
class Generator(nn.Module):
def __init__(self, ngpu):
super(Generator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
# input is Z, going into a convolution
nn.ConvTranspose2d( nz, ngf * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(ngf * 8),
nn.ReLU(True),
# state size. (ngf*8) x 4 x 4
nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
# state size. (ngf*4) x 8 x 8
nn.ConvTranspose2d( ngf * 4, ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
# state size. (ngf*2) x 16 x 16
nn.ConvTranspose2d( ngf * 2, ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
# state size. (ngf) x 32 x 32
nn.ConvTranspose2d( ngf, nc, 4, 2, 1, bias=False),
nn.Tanh()
# state size. (nc) x 64 x 64
)
def forward(self, input):
return self.main(input)
Now, we can instantiate the generator and apply the weights_init
function. Check out the printed model to see how the generator object is
structured.
# Create the generator
netG = Generator(ngpu).to(device)
# Handle multi-gpu if desired
if (device.type == 'cuda') and (ngpu > 1):
netG = nn.DataParallel(netG, list(range(ngpu)))
# Apply the weights_init function to randomly initialize all weights
# to mean=0, stdev=0.2.
netG.apply(weights_init)
# Print the model
print(netG)
Out:
Generator(
(main): Sequential(
(0): ConvTranspose2d(100, 512, kernel_size=(4, 4), stride=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
(3): ConvTranspose2d(512, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace)
(6): ConvTranspose2d(256, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(7): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(8): ReLU(inplace)
(9): ConvTranspose2d(128, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(10): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(11): ReLU(inplace)
(12): ConvTranspose2d(64, 3, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(13): Tanh()
)
)
Discriminator¶
As mentioned, the discriminator, \(D\), is a binary classification network that takes an image as input and outputs a scalar probability that the input image is real (as opposed to fake). Here, \(D\) takes a 3x64x64 input image, processes it through a series of Conv2d, BatchNorm2d, and LeakyReLU layers, and outputs the final probability through a Sigmoid activation function. This architecture can be extended with more layers if necessary for the problem, but there is significance to the use of the strided convolution, BatchNorm, and LeakyReLUs. The DCGAN paper mentions it is a good practice to use strided convolution rather than pooling to downsample because it lets the network learn its own pooling function. Also batch norm and leaky relu functions promote healthy gradient flow which is critical for the learning process of both \(G\) and \(D\).
Discriminator Code
class Discriminator(nn.Module):
def __init__(self, ngpu):
super(Discriminator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
# input is (nc) x 64 x 64
nn.Conv2d(nc, ndf, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf) x 32 x 32
nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*2) x 16 x 16
nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*4) x 8 x 8
nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*8) x 4 x 4
nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
)
def forward(self, input):
return self.main(input)
Now, as with the generator, we can create the discriminator, apply the
weights_init function, and print the model’s structure.
# Create the Discriminator
netD = Discriminator(ngpu).to(device)
# Handle multi-gpu if desired
if (device.type == 'cuda') and (ngpu > 1):
netD = nn.DataParallel(netD, list(range(ngpu)))
# Apply the weights_init function to randomly initialize all weights
# to mean=0, stdev=0.2.
netD.apply(weights_init)
# Print the model
print(netD)
Out:
Discriminator(
(main): Sequential(
(0): Conv2d(3, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): LeakyReLU(negative_slope=0.2, inplace)
(2): Conv2d(64, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(4): LeakyReLU(negative_slope=0.2, inplace)
(5): Conv2d(128, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(6): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(7): LeakyReLU(negative_slope=0.2, inplace)
(8): Conv2d(256, 512, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(9): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(10): LeakyReLU(negative_slope=0.2, inplace)
(11): Conv2d(512, 1, kernel_size=(4, 4), stride=(1, 1), bias=False)
(12): Sigmoid()
)
)
Loss Functions and Optimizers¶
With \(D\) and \(G\) setup, we can specify how they learn through the loss functions and optimizers. We will use the Binary Cross Entropy loss (BCELoss) function which is defined in PyTorch as:
Notice how this function provides the calculation of both log components in the objective function (i.e. \(log(D(x))\) and \(log(1-D(G(z)))\)). We can specify what part of the BCE equation to use with the \(y\) input. This is accomplished in the training loop which is coming up soon, but it is important to understand how we can choose which component we wish to calculate just by changing \(y\) (i.e. GT labels).
Next, we define our real label as 1 and the fake label as 0. These labels will be used when calculating the losses of \(D\) and \(G\), and this is also the convention used in the original GAN paper. Finally, we set up two separate optimizers, one for \(D\) and one for \(G\). As specified in the DCGAN paper, both are Adam optimizers with learning rate 0.0002 and Beta1 = 0.5. For keeping track of the generator’s learning progression, we will generate a fixed batch of latent vectors that are drawn from a Gaussian distribution (i.e. fixed_noise) . In the training loop, we will periodically input this fixed_noise into \(G\), and over the iterations we will see images form out of the noise.
# Initialize BCELoss function
criterion = nn.BCELoss()
# Create batch of latent vectors that we will use to visualize
# the progression of the generator
fixed_noise = torch.randn(64, nz, 1, 1, device=device)
# Establish convention for real and fake labels during training
real_label = 1
fake_label = 0
# Setup Adam optimizers for both G and D
optimizerD = optim.Adam(netD.parameters(), lr=lr, betas=(beta1, 0.999))
optimizerG = optim.Adam(netG.parameters(), lr=lr, betas=(beta1, 0.999))
Training¶
Finally, now that we have all of the parts of the GAN framework defined, we can train it. Be mindful that training GANs is somewhat of an art form, as incorrect hyperparameter settings lead to mode collapse with little explanation of what went wrong. Here, we will closely follow Algorithm 1 from Goodfellow’s paper, while abiding by some of the best practices shown in ganhacks. Namely, we will “construct different mini-batches for real and fake” images, and also adjust G’s objective function to maximize \(logD(G(z))\). Training is split up into two main parts. Part 1 updates the Discriminator and Part 2 updates the Generator.
Part 1 - Train the Discriminator
Recall, the goal of training the discriminator is to maximize the probability of correctly classifying a given input as real or fake. In terms of Goodfellow, we wish to “update the discriminator by ascending its stochastic gradient”. Practically, we want to maximize \(log(D(x)) + log(1-D(G(z)))\). Due to the separate mini-batch suggestion from ganhacks, we will calculate this in two steps. First, we will construct a batch of real samples from the training set, forward pass through \(D\), calculate the loss (\(log(D(x))\)), then calculate the gradients in a backward pass. Secondly, we will construct a batch of fake samples with the current generator, forward pass this batch through \(D\), calculate the loss (\(log(1-D(G(z)))\)), and accumulate the gradients with a backward pass. Now, with the gradients accumulated from both the all-real and all-fake batches, we call a step of the Discriminator’s optimizer.
Part 2 - Train the Generator
As stated in the original paper, we want to train the Generator by minimizing \(log(1-D(G(z)))\) in an effort to generate better fakes. As mentioned, this was shown by Goodfellow to not provide sufficient gradients, especially early in the learning process. As a fix, we instead wish to maximize \(log(D(G(z)))\). In the code we accomplish this by: classifying the Generator output from Part 1 with the Discriminator, computing G’s loss using real labels as GT, computing G’s gradients in a backward pass, and finally updating G’s parameters with an optimizer step. It may seem counter-intuitive to use the real labels as GT labels for the loss function, but this allows us to use the \(log(x)\) part of the BCELoss (rather than the \(log(1-x)\) part) which is exactly what we want.
Finally, we will do some statistic reporting and at the end of each epoch we will push our fixed_noise batch through the generator to visually track the progress of G’s training. The training statistics reported are:
- Loss_D - discriminator loss calculated as the sum of losses for the all real and all fake batches (\(log(D(x)) + log(D(G(z)))\)).
- Loss_G - generator loss calculated as \(log(D(G(z)))\)
- D(x) - the average output (across the batch) of the discriminator for the all real batch. This should start close to 1 then theoretically converge to 0.5 when G gets better. Think about why this is.
- D(G(z)) - average discriminator outputs for the all fake batch. The first number is before D is updated and the second number is after D is updated. These numbers should start near 0 and converge to 0.5 as G gets better. Think about why this is.
Note: This step might take a while, depending on how many epochs you run and if you removed some data from the dataset.
# Training Loop
# Lists to keep track of progress
img_list = []
G_losses = []
D_losses = []
iters = 0
print("Starting Training Loop...")
# For each epoch
for epoch in range(num_epochs):
# For each batch in the dataloader
for i, data in enumerate(dataloader, 0):
############################
# (1) Update D network: maximize log(D(x)) + log(1 - D(G(z)))
###########################
## Train with all-real batch
netD.zero_grad()
# Format batch
real_cpu = data[0].to(device)
b_size = real_cpu.size(0)
label = torch.full((b_size,), real_label, device=device)
# Forward pass real batch through D
output = netD(real_cpu).view(-1)
# Calculate loss on all-real batch
errD_real = criterion(output, label)
# Calculate gradients for D in backward pass
errD_real.backward()
D_x = output.mean().item()
## Train with all-fake batch
# Generate batch of latent vectors
noise = torch.randn(b_size, nz, 1, 1, device=device)
# Generate fake image batch with G
fake = netG(noise)
label.fill_(fake_label)
# Classify all fake batch with D
output = netD(fake.detach()).view(-1)
# Calculate D's loss on the all-fake batch
errD_fake = criterion(output, label)
# Calculate the gradients for this batch
errD_fake.backward()
D_G_z1 = output.mean().item()
# Add the gradients from the all-real and all-fake batches
errD = errD_real + errD_fake
# Update D
optimizerD.step()
############################
# (2) Update G network: maximize log(D(G(z)))
###########################
netG.zero_grad()
label.fill_(real_label) # fake labels are real for generator cost
# Since we just updated D, perform another forward pass of all-fake batch through D
output = netD(fake).view(-1)
# Calculate G's loss based on this output
errG = criterion(output, label)
# Calculate gradients for G
errG.backward()
D_G_z2 = output.mean().item()
# Update G
optimizerG.step()
# Output training stats
if i % 50 == 0:
print('[%d/%d][%d/%d]\tLoss_D: %.4f\tLoss_G: %.4f\tD(x): %.4f\tD(G(z)): %.4f / %.4f'
% (epoch, num_epochs, i, len(dataloader),
errD.item(), errG.item(), D_x, D_G_z1, D_G_z2))
# Save Losses for plotting later
G_losses.append(errG.item())
D_losses.append(errD.item())
# Check how the generator is doing by saving G's output on fixed_noise
if (iters % 500 == 0) or ((epoch == num_epochs-1) and (i == len(dataloader)-1)):
with torch.no_grad():
fake = netG(fixed_noise).detach().cpu()
img_list.append(vutils.make_grid(fake, padding=2, normalize=True))
iters += 1
Out:
Starting Training Loop...
[0/5][0/1583] Loss_D: 1.7410 Loss_G: 4.7761 D(x): 0.5343 D(G(z)): 0.5771 / 0.0136
[0/5][50/1583] Loss_D: 0.0036 Loss_G: 32.4314 D(x): 0.9969 D(G(z)): 0.0000 / 0.0000
[0/5][100/1583] Loss_D: 0.4648 Loss_G: 13.2077 D(x): 0.9309 D(G(z)): 0.2421 / 0.0000
[0/5][150/1583] Loss_D: 0.4786 Loss_G: 4.1579 D(x): 0.7766 D(G(z)): 0.1089 / 0.0264
[0/5][200/1583] Loss_D: 1.2703 Loss_G: 3.4091 D(x): 0.4108 D(G(z)): 0.0094 / 0.0531
[0/5][250/1583] Loss_D: 0.7417 Loss_G: 5.3030 D(x): 0.8287 D(G(z)): 0.2921 / 0.0132
[0/5][300/1583] Loss_D: 0.4811 Loss_G: 3.8799 D(x): 0.7413 D(G(z)): 0.0682 / 0.0395
[0/5][350/1583] Loss_D: 0.3455 Loss_G: 3.8807 D(x): 0.8529 D(G(z)): 0.1196 / 0.0388
[0/5][400/1583] Loss_D: 0.6372 Loss_G: 4.8584 D(x): 0.6536 D(G(z)): 0.0147 / 0.0175
[0/5][450/1583] Loss_D: 0.3318 Loss_G: 5.1119 D(x): 0.8481 D(G(z)): 0.0892 / 0.0129
[0/5][500/1583] Loss_D: 0.4976 Loss_G: 5.4097 D(x): 0.7418 D(G(z)): 0.0672 / 0.0157
[0/5][550/1583] Loss_D: 0.5481 Loss_G: 4.2423 D(x): 0.8279 D(G(z)): 0.1936 / 0.0247
[0/5][600/1583] Loss_D: 0.4953 Loss_G: 7.6697 D(x): 0.9340 D(G(z)): 0.2945 / 0.0010
[0/5][650/1583] Loss_D: 1.0586 Loss_G: 7.9784 D(x): 0.9717 D(G(z)): 0.5530 / 0.0009
[0/5][700/1583] Loss_D: 0.7680 Loss_G: 5.6792 D(x): 0.8613 D(G(z)): 0.3773 / 0.0078
[0/5][750/1583] Loss_D: 0.4436 Loss_G: 2.8845 D(x): 0.7371 D(G(z)): 0.0574 / 0.0771
[0/5][800/1583] Loss_D: 0.4764 Loss_G: 4.4193 D(x): 0.7552 D(G(z)): 0.0848 / 0.0308
[0/5][850/1583] Loss_D: 0.4949 Loss_G: 4.6610 D(x): 0.8849 D(G(z)): 0.2627 / 0.0167
[0/5][900/1583] Loss_D: 0.3727 Loss_G: 4.1653 D(x): 0.8007 D(G(z)): 0.0842 / 0.0278
[0/5][950/1583] Loss_D: 0.6115 Loss_G: 4.4391 D(x): 0.7630 D(G(z)): 0.1930 / 0.0253
[0/5][1000/1583] Loss_D: 1.0966 Loss_G: 8.6152 D(x): 0.9503 D(G(z)): 0.5594 / 0.0005
[0/5][1050/1583] Loss_D: 0.6567 Loss_G: 6.1102 D(x): 0.9031 D(G(z)): 0.3535 / 0.0057
[0/5][1100/1583] Loss_D: 0.5739 Loss_G: 2.1241 D(x): 0.7183 D(G(z)): 0.1276 / 0.1628
[0/5][1150/1583] Loss_D: 0.6654 Loss_G: 6.2700 D(x): 0.8958 D(G(z)): 0.3766 / 0.0029
[0/5][1200/1583] Loss_D: 0.5377 Loss_G: 4.7223 D(x): 0.8644 D(G(z)): 0.2882 / 0.0130
[0/5][1250/1583] Loss_D: 0.5589 Loss_G: 5.3205 D(x): 0.8808 D(G(z)): 0.2745 / 0.0124
[0/5][1300/1583] Loss_D: 0.4369 Loss_G: 4.6506 D(x): 0.8448 D(G(z)): 0.1948 / 0.0139
[0/5][1350/1583] Loss_D: 0.4043 Loss_G: 3.6173 D(x): 0.7819 D(G(z)): 0.0916 / 0.0441
[0/5][1400/1583] Loss_D: 0.5956 Loss_G: 4.8434 D(x): 0.9272 D(G(z)): 0.3565 / 0.0153
[0/5][1450/1583] Loss_D: 0.4745 Loss_G: 4.0462 D(x): 0.8664 D(G(z)): 0.2423 / 0.0270
[0/5][1500/1583] Loss_D: 0.3860 Loss_G: 3.5699 D(x): 0.8183 D(G(z)): 0.1354 / 0.0439
[0/5][1550/1583] Loss_D: 0.2764 Loss_G: 4.3084 D(x): 0.9112 D(G(z)): 0.1527 / 0.0208
[1/5][0/1583] Loss_D: 0.7259 Loss_G: 5.6982 D(x): 0.8964 D(G(z)): 0.3968 / 0.0066
[1/5][50/1583] Loss_D: 0.3376 Loss_G: 3.3593 D(x): 0.8560 D(G(z)): 0.1432 / 0.0511
[1/5][100/1583] Loss_D: 0.4806 Loss_G: 3.2101 D(x): 0.8298 D(G(z)): 0.2145 / 0.0662
[1/5][150/1583] Loss_D: 0.4912 Loss_G: 2.8198 D(x): 0.7516 D(G(z)): 0.1292 / 0.0937
[1/5][200/1583] Loss_D: 0.5770 Loss_G: 2.1488 D(x): 0.6701 D(G(z)): 0.0704 / 0.1704
[1/5][250/1583] Loss_D: 0.5188 Loss_G: 2.7125 D(x): 0.7073 D(G(z)): 0.0698 / 0.1080
[1/5][300/1583] Loss_D: 0.4184 Loss_G: 3.1331 D(x): 0.7731 D(G(z)): 0.0908 / 0.0707
[1/5][350/1583] Loss_D: 0.8507 Loss_G: 5.4583 D(x): 0.9205 D(G(z)): 0.4772 / 0.0095
[1/5][400/1583] Loss_D: 0.3165 Loss_G: 3.3879 D(x): 0.8452 D(G(z)): 0.1117 / 0.0473
[1/5][450/1583] Loss_D: 0.6153 Loss_G: 2.4943 D(x): 0.7141 D(G(z)): 0.1763 / 0.1092
[1/5][500/1583] Loss_D: 0.5050 Loss_G: 2.6065 D(x): 0.7745 D(G(z)): 0.1834 / 0.1021
[1/5][550/1583] Loss_D: 0.6305 Loss_G: 5.1587 D(x): 0.9255 D(G(z)): 0.3783 / 0.0099
[1/5][600/1583] Loss_D: 0.6357 Loss_G: 4.2457 D(x): 0.8789 D(G(z)): 0.3560 / 0.0205
[1/5][650/1583] Loss_D: 0.7014 Loss_G: 4.6448 D(x): 0.8999 D(G(z)): 0.3966 / 0.0172
[1/5][700/1583] Loss_D: 0.4781 Loss_G: 2.9270 D(x): 0.8131 D(G(z)): 0.1969 / 0.0723
[1/5][750/1583] Loss_D: 0.5873 Loss_G: 3.2436 D(x): 0.8543 D(G(z)): 0.2754 / 0.0622
[1/5][800/1583] Loss_D: 2.8152 Loss_G: 5.7494 D(x): 0.9906 D(G(z)): 0.8873 / 0.0093
[1/5][850/1583] Loss_D: 0.5920 Loss_G: 4.5367 D(x): 0.8910 D(G(z)): 0.3325 / 0.0166
[1/5][900/1583] Loss_D: 1.2057 Loss_G: 0.7460 D(x): 0.3996 D(G(z)): 0.0538 / 0.5395
[1/5][950/1583] Loss_D: 0.4588 Loss_G: 3.0682 D(x): 0.8248 D(G(z)): 0.1925 / 0.0726
[1/5][1000/1583] Loss_D: 0.5912 Loss_G: 4.9266 D(x): 0.9208 D(G(z)): 0.3520 / 0.0105
[1/5][1050/1583] Loss_D: 0.4624 Loss_G: 2.2692 D(x): 0.7061 D(G(z)): 0.0543 / 0.1432
[1/5][1100/1583] Loss_D: 0.7717 Loss_G: 4.6740 D(x): 0.8968 D(G(z)): 0.4309 / 0.0164
[1/5][1150/1583] Loss_D: 0.5989 Loss_G: 1.8450 D(x): 0.7178 D(G(z)): 0.1852 / 0.2011
[1/5][1200/1583] Loss_D: 0.5555 Loss_G: 1.4898 D(x): 0.7129 D(G(z)): 0.1312 / 0.2736
[1/5][1250/1583] Loss_D: 0.7487 Loss_G: 5.5522 D(x): 0.9525 D(G(z)): 0.4519 / 0.0060
[1/5][1300/1583] Loss_D: 1.0852 Loss_G: 4.9686 D(x): 0.9756 D(G(z)): 0.5945 / 0.0123
[1/5][1350/1583] Loss_D: 0.6924 Loss_G: 3.1922 D(x): 0.7981 D(G(z)): 0.3214 / 0.0614
[1/5][1400/1583] Loss_D: 0.7107 Loss_G: 2.9181 D(x): 0.7290 D(G(z)): 0.2772 / 0.0721
[1/5][1450/1583] Loss_D: 0.5716 Loss_G: 3.6768 D(x): 0.8756 D(G(z)): 0.3041 / 0.0392
[1/5][1500/1583] Loss_D: 1.1166 Loss_G: 5.3574 D(x): 0.9584 D(G(z)): 0.6126 / 0.0072
[1/5][1550/1583] Loss_D: 0.5379 Loss_G: 2.1021 D(x): 0.7256 D(G(z)): 0.1521 / 0.1529
[2/5][0/1583] Loss_D: 0.4310 Loss_G: 2.7433 D(x): 0.7413 D(G(z)): 0.0900 / 0.0834
[2/5][50/1583] Loss_D: 0.5860 Loss_G: 1.7170 D(x): 0.7096 D(G(z)): 0.1606 / 0.2301
[2/5][100/1583] Loss_D: 0.6583 Loss_G: 1.6706 D(x): 0.6466 D(G(z)): 0.1276 / 0.2297
[2/5][150/1583] Loss_D: 0.7551 Loss_G: 2.8574 D(x): 0.8610 D(G(z)): 0.4141 / 0.0729
[2/5][200/1583] Loss_D: 0.5421 Loss_G: 2.8993 D(x): 0.8434 D(G(z)): 0.2801 / 0.0723
[2/5][250/1583] Loss_D: 0.6752 Loss_G: 1.9487 D(x): 0.6335 D(G(z)): 0.1300 / 0.1862
[2/5][300/1583] Loss_D: 0.7367 Loss_G: 3.9978 D(x): 0.8898 D(G(z)): 0.4136 / 0.0292
[2/5][350/1583] Loss_D: 1.1935 Loss_G: 5.6641 D(x): 0.9283 D(G(z)): 0.6214 / 0.0053
[2/5][400/1583] Loss_D: 0.7003 Loss_G: 2.5934 D(x): 0.7014 D(G(z)): 0.2329 / 0.1029
[2/5][450/1583] Loss_D: 0.6855 Loss_G: 2.7080 D(x): 0.8091 D(G(z)): 0.3380 / 0.0871
[2/5][500/1583] Loss_D: 0.5109 Loss_G: 2.2182 D(x): 0.7444 D(G(z)): 0.1575 / 0.1434
[2/5][550/1583] Loss_D: 0.5341 Loss_G: 2.2072 D(x): 0.7191 D(G(z)): 0.1399 / 0.1540
[2/5][600/1583] Loss_D: 0.8182 Loss_G: 3.8690 D(x): 0.9140 D(G(z)): 0.4704 / 0.0310
[2/5][650/1583] Loss_D: 0.7203 Loss_G: 3.5071 D(x): 0.8925 D(G(z)): 0.4080 / 0.0438
[2/5][700/1583] Loss_D: 1.0450 Loss_G: 0.8684 D(x): 0.4326 D(G(z)): 0.0457 / 0.4777
[2/5][750/1583] Loss_D: 0.9090 Loss_G: 1.5100 D(x): 0.4895 D(G(z)): 0.0672 / 0.2769
[2/5][800/1583] Loss_D: 0.7232 Loss_G: 4.2397 D(x): 0.9078 D(G(z)): 0.4146 / 0.0215
[2/5][850/1583] Loss_D: 0.6635 Loss_G: 3.0495 D(x): 0.8413 D(G(z)): 0.3407 / 0.0663
[2/5][900/1583] Loss_D: 0.8238 Loss_G: 3.5242 D(x): 0.8986 D(G(z)): 0.4620 / 0.0423
[2/5][950/1583] Loss_D: 1.5066 Loss_G: 5.5479 D(x): 0.8970 D(G(z)): 0.7055 / 0.0126
[2/5][1000/1583] Loss_D: 0.6975 Loss_G: 3.3240 D(x): 0.8179 D(G(z)): 0.3497 / 0.0510
[2/5][1050/1583] Loss_D: 1.0930 Loss_G: 3.7646 D(x): 0.9441 D(G(z)): 0.5922 / 0.0317
[2/5][1100/1583] Loss_D: 0.4088 Loss_G: 2.8833 D(x): 0.8301 D(G(z)): 0.1809 / 0.0741
[2/5][1150/1583] Loss_D: 0.6162 Loss_G: 2.9347 D(x): 0.8181 D(G(z)): 0.2802 / 0.0697
[2/5][1200/1583] Loss_D: 0.5197 Loss_G: 1.7128 D(x): 0.7235 D(G(z)): 0.1428 / 0.2165
[2/5][1250/1583] Loss_D: 0.5586 Loss_G: 3.1516 D(x): 0.8995 D(G(z)): 0.3243 / 0.0615
[2/5][1300/1583] Loss_D: 0.5934 Loss_G: 2.4434 D(x): 0.7195 D(G(z)): 0.1836 / 0.1118
[2/5][1350/1583] Loss_D: 0.5352 Loss_G: 2.0955 D(x): 0.6930 D(G(z)): 0.1142 / 0.1448
[2/5][1400/1583] Loss_D: 1.3824 Loss_G: 4.8543 D(x): 0.9538 D(G(z)): 0.6681 / 0.0131
[2/5][1450/1583] Loss_D: 0.8523 Loss_G: 2.9794 D(x): 0.7852 D(G(z)): 0.4027 / 0.0698
[2/5][1500/1583] Loss_D: 1.3982 Loss_G: 4.0329 D(x): 0.9418 D(G(z)): 0.6790 / 0.0269
[2/5][1550/1583] Loss_D: 0.8623 Loss_G: 0.9329 D(x): 0.6102 D(G(z)): 0.2352 / 0.4310
[3/5][0/1583] Loss_D: 0.4663 Loss_G: 2.7662 D(x): 0.7885 D(G(z)): 0.1727 / 0.0865
[3/5][50/1583] Loss_D: 0.7566 Loss_G: 1.3576 D(x): 0.6275 D(G(z)): 0.1710 / 0.3106
[3/5][100/1583] Loss_D: 0.7194 Loss_G: 1.7730 D(x): 0.5686 D(G(z)): 0.0473 / 0.2104
[3/5][150/1583] Loss_D: 1.4109 Loss_G: 5.2130 D(x): 0.9147 D(G(z)): 0.6899 / 0.0107
[3/5][200/1583] Loss_D: 0.5690 Loss_G: 3.6056 D(x): 0.8928 D(G(z)): 0.3383 / 0.0343
[3/5][250/1583] Loss_D: 0.6108 Loss_G: 2.0417 D(x): 0.6150 D(G(z)): 0.0613 / 0.1676
[3/5][300/1583] Loss_D: 0.8488 Loss_G: 3.0175 D(x): 0.8009 D(G(z)): 0.4168 / 0.0610
[3/5][350/1583] Loss_D: 0.4872 Loss_G: 2.2599 D(x): 0.7672 D(G(z)): 0.1670 / 0.1264
[3/5][400/1583] Loss_D: 0.7258 Loss_G: 1.5676 D(x): 0.6045 D(G(z)): 0.1505 / 0.2537
[3/5][450/1583] Loss_D: 0.8158 Loss_G: 1.8989 D(x): 0.7045 D(G(z)): 0.3178 / 0.1838
[3/5][500/1583] Loss_D: 0.5820 Loss_G: 2.2274 D(x): 0.6950 D(G(z)): 0.1484 / 0.1343
[3/5][550/1583] Loss_D: 0.6494 Loss_G: 3.1375 D(x): 0.8439 D(G(z)): 0.3403 / 0.0607
[3/5][600/1583] Loss_D: 0.5916 Loss_G: 1.6829 D(x): 0.6703 D(G(z)): 0.1283 / 0.2217
[3/5][650/1583] Loss_D: 0.3782 Loss_G: 2.4780 D(x): 0.8417 D(G(z)): 0.1634 / 0.1096
[3/5][700/1583] Loss_D: 0.5283 Loss_G: 3.2549 D(x): 0.9060 D(G(z)): 0.3271 / 0.0484
[3/5][750/1583] Loss_D: 0.6846 Loss_G: 2.4028 D(x): 0.8643 D(G(z)): 0.3770 / 0.1189
[3/5][800/1583] Loss_D: 0.5950 Loss_G: 2.5773 D(x): 0.7686 D(G(z)): 0.2485 / 0.0993
[3/5][850/1583] Loss_D: 0.7142 Loss_G: 1.6371 D(x): 0.7235 D(G(z)): 0.2772 / 0.2265
[3/5][900/1583] Loss_D: 0.8419 Loss_G: 1.9102 D(x): 0.6717 D(G(z)): 0.2765 / 0.1874
[3/5][950/1583] Loss_D: 0.6532 Loss_G: 3.0450 D(x): 0.9047 D(G(z)): 0.3912 / 0.0605
[3/5][1000/1583] Loss_D: 0.5910 Loss_G: 2.6276 D(x): 0.8147 D(G(z)): 0.2837 / 0.0960
[3/5][1050/1583] Loss_D: 0.6414 Loss_G: 2.3586 D(x): 0.7317 D(G(z)): 0.2351 / 0.1167
[3/5][1100/1583] Loss_D: 0.7069 Loss_G: 2.1957 D(x): 0.7231 D(G(z)): 0.2646 / 0.1387
[3/5][1150/1583] Loss_D: 1.3866 Loss_G: 0.3103 D(x): 0.3365 D(G(z)): 0.0466 / 0.7761
[3/5][1200/1583] Loss_D: 0.7221 Loss_G: 1.4965 D(x): 0.5658 D(G(z)): 0.0633 / 0.2636
[3/5][1250/1583] Loss_D: 0.5758 Loss_G: 1.8856 D(x): 0.7192 D(G(z)): 0.1764 / 0.1824
[3/5][1300/1583] Loss_D: 0.7380 Loss_G: 2.9522 D(x): 0.8877 D(G(z)): 0.4299 / 0.0660
[3/5][1350/1583] Loss_D: 0.5744 Loss_G: 2.5502 D(x): 0.7662 D(G(z)): 0.2270 / 0.1008
[3/5][1400/1583] Loss_D: 0.5810 Loss_G: 3.3073 D(x): 0.8693 D(G(z)): 0.3251 / 0.0474
[3/5][1450/1583] Loss_D: 0.8003 Loss_G: 1.2474 D(x): 0.5865 D(G(z)): 0.1652 / 0.3417
[3/5][1500/1583] Loss_D: 0.5466 Loss_G: 3.1508 D(x): 0.8764 D(G(z)): 0.3026 / 0.0585
[3/5][1550/1583] Loss_D: 0.8004 Loss_G: 2.8298 D(x): 0.7451 D(G(z)): 0.3440 / 0.0820
[4/5][0/1583] Loss_D: 0.6308 Loss_G: 1.6824 D(x): 0.6569 D(G(z)): 0.1446 / 0.2186
[4/5][50/1583] Loss_D: 0.4493 Loss_G: 2.4370 D(x): 0.7526 D(G(z)): 0.1205 / 0.1119
[4/5][100/1583] Loss_D: 1.2206 Loss_G: 0.6096 D(x): 0.3816 D(G(z)): 0.0534 / 0.5886
[4/5][150/1583] Loss_D: 2.1607 Loss_G: 4.6582 D(x): 0.9683 D(G(z)): 0.8385 / 0.0168
[4/5][200/1583] Loss_D: 0.9957 Loss_G: 3.7864 D(x): 0.9467 D(G(z)): 0.5574 / 0.0322
[4/5][250/1583] Loss_D: 0.5801 Loss_G: 2.5348 D(x): 0.8681 D(G(z)): 0.3236 / 0.0984
[4/5][300/1583] Loss_D: 2.1208 Loss_G: 0.3579 D(x): 0.1774 D(G(z)): 0.0294 / 0.7390
[4/5][350/1583] Loss_D: 0.5843 Loss_G: 2.5555 D(x): 0.7926 D(G(z)): 0.2541 / 0.0985
[4/5][400/1583] Loss_D: 0.4502 Loss_G: 2.3482 D(x): 0.7604 D(G(z)): 0.1311 / 0.1233
[4/5][450/1583] Loss_D: 0.5906 Loss_G: 2.3183 D(x): 0.8016 D(G(z)): 0.2720 / 0.1270
[4/5][500/1583] Loss_D: 0.3696 Loss_G: 3.6228 D(x): 0.9039 D(G(z)): 0.2173 / 0.0346
[4/5][550/1583] Loss_D: 1.0966 Loss_G: 1.2723 D(x): 0.4247 D(G(z)): 0.0552 / 0.3412
[4/5][600/1583] Loss_D: 0.5086 Loss_G: 2.3477 D(x): 0.6983 D(G(z)): 0.1046 / 0.1235
[4/5][650/1583] Loss_D: 1.0586 Loss_G: 4.5255 D(x): 0.9458 D(G(z)): 0.5840 / 0.0183
[4/5][700/1583] Loss_D: 0.5717 Loss_G: 2.1600 D(x): 0.7767 D(G(z)): 0.2427 / 0.1388
[4/5][750/1583] Loss_D: 0.8340 Loss_G: 1.5340 D(x): 0.6236 D(G(z)): 0.2196 / 0.2547
[4/5][800/1583] Loss_D: 0.4782 Loss_G: 2.8809 D(x): 0.8406 D(G(z)): 0.2371 / 0.0709
[4/5][850/1583] Loss_D: 1.2544 Loss_G: 0.8528 D(x): 0.3579 D(G(z)): 0.0369 / 0.4901
[4/5][900/1583] Loss_D: 1.6921 Loss_G: 0.3693 D(x): 0.2461 D(G(z)): 0.0318 / 0.7254
[4/5][950/1583] Loss_D: 0.7190 Loss_G: 1.4799 D(x): 0.5842 D(G(z)): 0.0773 / 0.2757
[4/5][1000/1583] Loss_D: 1.5300 Loss_G: 0.8840 D(x): 0.2668 D(G(z)): 0.0101 / 0.4571
[4/5][1050/1583] Loss_D: 0.6022 Loss_G: 2.3410 D(x): 0.7327 D(G(z)): 0.2079 / 0.1214
[4/5][1100/1583] Loss_D: 0.6978 Loss_G: 1.3334 D(x): 0.5987 D(G(z)): 0.0955 / 0.3067
[4/5][1150/1583] Loss_D: 0.6395 Loss_G: 2.9988 D(x): 0.8697 D(G(z)): 0.3612 / 0.0650
[4/5][1200/1583] Loss_D: 0.5782 Loss_G: 2.0590 D(x): 0.7386 D(G(z)): 0.1950 / 0.1559
[4/5][1250/1583] Loss_D: 0.6848 Loss_G: 1.7482 D(x): 0.5989 D(G(z)): 0.1054 / 0.2123
[4/5][1300/1583] Loss_D: 0.5878 Loss_G: 2.1105 D(x): 0.7472 D(G(z)): 0.2213 / 0.1493
[4/5][1350/1583] Loss_D: 0.4586 Loss_G: 2.9239 D(x): 0.8489 D(G(z)): 0.2236 / 0.0723
[4/5][1400/1583] Loss_D: 0.8891 Loss_G: 3.6426 D(x): 0.8969 D(G(z)): 0.4772 / 0.0391
[4/5][1450/1583] Loss_D: 0.6161 Loss_G: 2.8486 D(x): 0.8180 D(G(z)): 0.3058 / 0.0762
[4/5][1500/1583] Loss_D: 2.6624 Loss_G: 0.7839 D(x): 0.1078 D(G(z)): 0.0195 / 0.5032
[4/5][1550/1583] Loss_D: 1.2092 Loss_G: 0.5122 D(x): 0.3585 D(G(z)): 0.0223 / 0.6408
Results¶
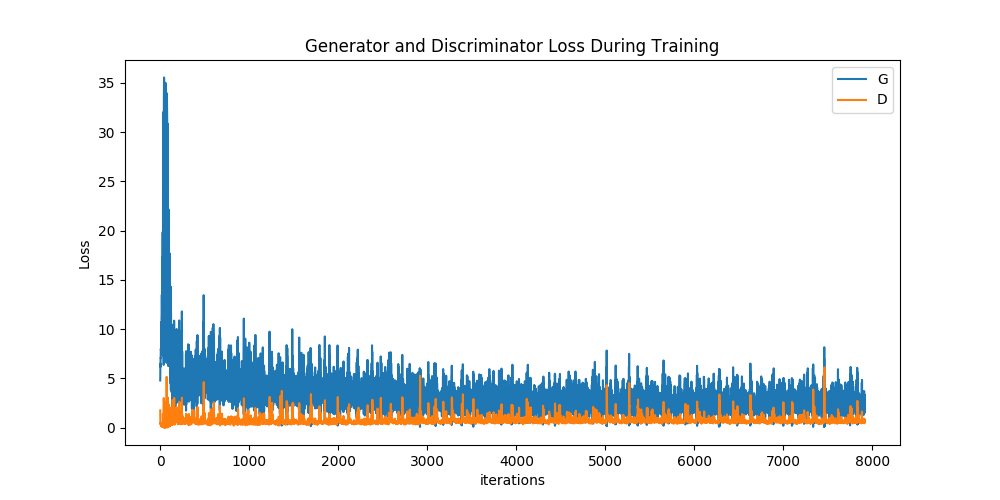
Finally, lets check out how we did. Here, we will look at three different results. First, we will see how D and G’s losses changed during training. Second, we will visualize G’s output on the fixed_noise batch for every epoch. And third, we will look at a batch of real data next to a batch of fake data from G.
Loss versus training iteration
Below is a plot of D & G’s losses versus training iterations.
plt.figure(figsize=(10,5))
plt.title("Generator and Discriminator Loss During Training")
plt.plot(G_losses,label="G")
plt.plot(D_losses,label="D")
plt.xlabel("iterations")
plt.ylabel("Loss")
plt.legend()
plt.show()
Visualization of G’s progression
Remember how we saved the generator’s output on the fixed_noise batch after every epoch of training. Now, we can visualize the training progression of G with an animation. Press the play button to start the animation.
#%%capture
fig = plt.figure(figsize=(8,8))
plt.axis("off")
ims = [[plt.imshow(np.transpose(i,(1,2,0)), animated=True)] for i in img_list]
ani = animation.ArtistAnimation(fig, ims, interval=1000, repeat_delay=1000, blit=True)
HTML(ani.to_jshtml())

Real Images vs. Fake Images
Finally, lets take a look at some real images and fake images side by side.
# Grab a batch of real images from the dataloader
real_batch = next(iter(dataloader))
# Plot the real images
plt.figure(figsize=(15,15))
plt.subplot(1,2,1)
plt.axis("off")
plt.title("Real Images")
plt.imshow(np.transpose(vutils.make_grid(real_batch[0].to(device)[:64], padding=5, normalize=True).cpu(),(1,2,0)))
# Plot the fake images from the last epoch
plt.subplot(1,2,2)
plt.axis("off")
plt.title("Fake Images")
plt.imshow(np.transpose(img_list[-1],(1,2,0)))
plt.show()

Where to Go Next¶
We have reached the end of our journey, but there are several places you could go from here. You could:
- Train for longer to see how good the results get
- Modify this model to take a different dataset and possibly change the size of the images and the model architecture
- Check out some other cool GAN projects here
- Create GANs that generate music
Total running time of the script: ( 28 minutes 20.863 seconds)